Context
AI is not intelligent. LLMs don’t “know” your organization. They only work as well as the data you feed them.
In the AI world, your documentation quality defines your AI quality. Enterprises rush to build Copilots with the knowledge scattered across PDFs, SharePoint folders, Confluence pages, Unstructured tickets and Email threads. RAG and Search systems fail or fall short of expectations not because of the model, but because of poor documentation structure.
Traditionally, documents like Policies, Architecture documents, Operational guidelines, Standards and procedures are written primarily for human readers.
Humans can easily interpret incomplete context, mixed topics and loosely organized sections.
However, modern AI-powered systems such as Enterprise Knowledge Bases, Semantic Search platforms, Retrieval-Augmented Generation (RAG) systems consume documentation very differently.
AI systems do not read documents as complete narratives. They process them as small independent chunks of text. Hence documentation structure directly affects AI performance.
Following diagram provides a snapshot of problem and the solution discussed in this article.
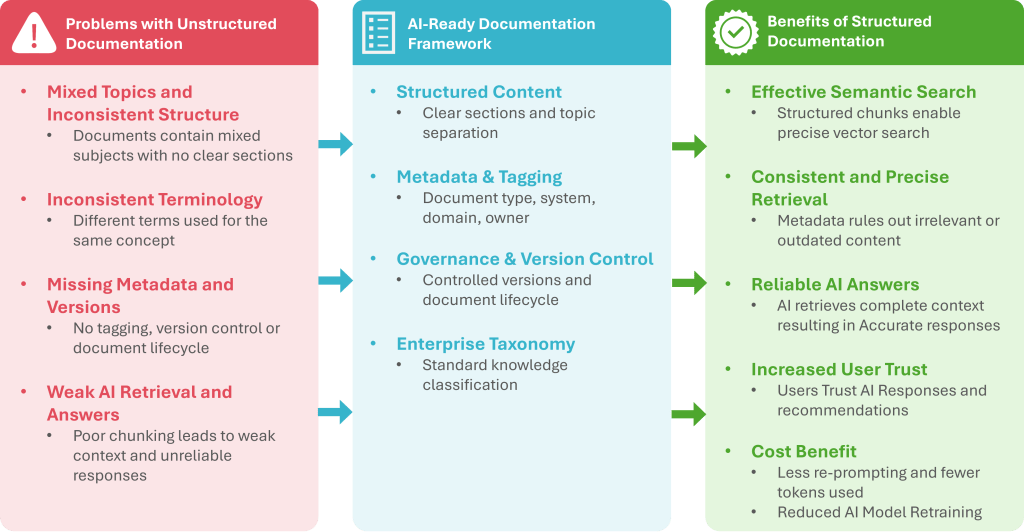
Fig 1 – From Unstructured Documentation to AI-Ready Framework
The Problem
Most Enterprise Documentation is unstructured. In many organizations, documentation evolves organically over time. Common characteristics include:
- Long documents mixing multiple topics
- Inconsistent section structure
- Lack of metadata or tagging
- Duplicate or outdated versions
- No clear relationship between documents
This may still work for humans, but it creates serious problems for AI-driven retrieval systems.
How Unstructured Documentation Creates Challenges for AI Systems
Logical Context can break during chunking process
RAG systems first divide documents into smaller segments called chunks before generating embeddings.
When documents are poorly structured, chunk boundaries may split important information across multiple chunks. The AI may retrieve incomplete or misleading context, resulting in incorrect answers.
Semantic Search May Retrieve the Wrong Content
Semantic search relies on embeddings representing meaning. Embeddings convert text into mathematical representations so AI systems can understand, and search information based on meaning, not just keywords. When documents mix multiple topics in the same section, the embeddings become noisy.
Suppose an architecture document section contains the following multiple topics in the same paragraph:
- Data Integration details
- Application Integration details
- API authentication details
When the document is chunked, all three topics may end up in the same chunk.
If a user searches for “API authentication mechanism”, the system retrieves that chunk. However, the retrieved text may mostly describe application integration details, because they were part of the same chunk.
As a result, the AI response may include irrelevant information about application integration instead of focusing on authentication.
Lack of Metadata Reduces Retrieval Precision
Enterprise AI search solutions work best with metadata filters such as document type, system name, domain, owner, version. When such metadata is missing, the system cannot narrow the search effectively.
Duplicate and Outdated Documents Confuse AI Systems
Organizations often store multiple versions of the same policy or guideline. Without proper versioning and governance, the AI system may use older policies and draft documents.
The language model may combine them and produce an answer that appears coherent but is not aligned with the current policy.
Can AI-Driven Dynamic Chunking Solve the Problem?
It may be argued that AI-Driven Dynamic Chunking can solve the unorganized and unstructured documentation.
Recent advances in AI-based chunking techniques attempt to mitigate these issues.
Some of the examples of such chunking strategies are:
- Semantic chunking
- Heading-aware chunking
- Adaptive chunk sizes
- Agentic chunking strategies
These methods try to identify natural boundaries in text rather than splitting purely by token count.
They can improve results in several ways including detecting topic shifts, grouping semantically related paragraphs and preserving contextual meaning
However, these techniques do not fully solve the problem.
Why AI Chunking cannot fully fix poor documentation?
Even the best chunking strategies still depend on the quality of the original content. AI chunking cannot reliably resolve:
Missing document hierarchy
If a document does not clearly separate sections, AI cannot always infer the intended structure.
Mixed topics within paragraphs
When different concepts appear in the same paragraph, chunking cannot isolate them.
Inconsistent terminology
Different teams may describe the same concept using different terms.
Missing metadata
Chunking cannot infer document ownership, system context, or version information.
In other words, AI can optimize chunking, but it cannot reconstruct knowledge architecture that was never designed.
The Solution: Designing Documentation for AI Retrieval
Organizations need to evolve documentation practices to support both human readability and AI retrieval. This requires adopting structured documentation principles. These principles are listed below.
Use clear Hierarchical Structure
Documents should follow a consistent structure:
- Title
- Scope
- Definitions
- Policy / Guidelines
- Implementation Details
- Exceptions
- References
This ensures that chunking algorithms can split content at meaningful boundaries.
Separate Topics into Independent Sections
Each section should represent a single knowledge concept.
Instead of mixing multiple ideas in one paragraph, separate them into dedicated sections. This improves:
- Quality of Embeddings
- Semantic search precision
- Retrieval relevance
Add Metadata and Tagging
Every document should include structured metadata such as:
- Document type
- System or domain
- Owner
- Version
- Creation date
- Keywords
This allows AI search systems to apply filtering and ranking strategies.
Maintain Version Governance
Only approved and current versions of documents should be indexed for AI search. Draft documents should be tagged for exclusion. Version control ensures that the knowledge base reflects the latest organizational guidance.
Establish a Knowledge Taxonomy
A taxonomy defines how knowledge is categorized across the organization.
Technology
- Architecture
- Security
- Integration
Operations
- Policies
- Guidelines
- Contracts
Taxonomies help both humans and AI systems navigate knowledge effectively.
The ROI of Structured Documentation
In the AI era, the benefits of structured documentation are not incremental. They are transformative and multiply across the organization.
Business Benefits
- Better Copilot answers
- Increased Data Democratization
- Reduced support tickets
- Faster onboarding
- Reduced compliance risk
- Lower AI operational cost
Cost Impact
- Fewer tokens used
- Less re-prompting
- Fewer failed searches
- Reduced AI model re-training
Conclusion
Before the rise of AI, poor documentation primarily caused human confusion.
In the age of AI, poor documentation directly reduces the accuracy, reliability, and trustworthiness of enterprise AI systems.
Organizations investing in AI must therefore recognize that, Structured documentation is no longer just a documentation practice — it is a foundational requirement for successful AI systems.
