In the bustling headquarters of a global e-commerce giant, chaos erupted as the AI-powered inventory management system inexplicably ordered a million units of a product that hadn’t sold in months. As executives scrambled to cancel the order and mitigate the financial fallout, a sobering realization dawned: their cutting-edge AI, touted as a game-changer, was only as good as the data it consumed. This cautionary tale underscores a critical truth in the age of artificial intelligence: data quality is the linchpin of success. As organizations rush to embrace the transformative power of AI and machine learning, many are learning a hard lesson: the promise of these technologies can quickly turn into peril when built upon a foundation of flawed data. With poor data quality costing organizations an average of $12.9 million annually, the stakes have never been higher. This article delves into the critical components of a robust data quality framework designed for the AI era, offering insights and strategies to transform your data from a liability into your most potent asset.
The Data Quality Framework: A Blueprint for Excellence
What separates AI trailblazers from those left in the digital dust? The answer lies not in algorithmic prowess alone, but in the often-overlooked foundation: a comprehensive data quality framework. Let’s embark on a journey through the essential components of such a framework, designed to elevate your data strategy and drive AI success.
The essential components are categorized under three layers:
- Foundational Layer
- Automation Layer
- Governance & Compliance Layer
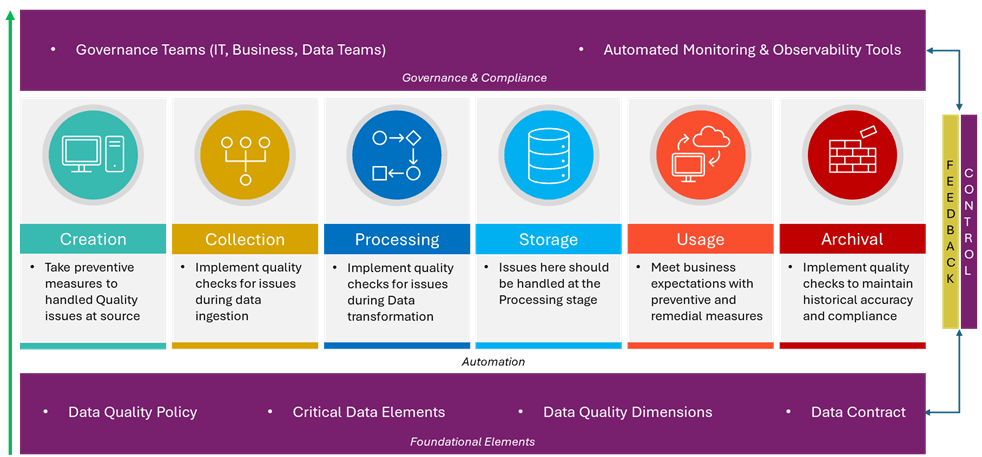
Fig-1: Essential Components of Data Quality Framework
Let’s dive into the layers in more detail.
1. Foundational Layer
Defining the Data Quality Policy
The cornerstone of any effective data quality initiative is a well-crafted policy. This policy serves as a north star, aligning business and IT stakeholders around shared expectations. A robust Data Quality Policy should:
- Clearly articulate the purpose and scope of data quality initiatives
- Outline key principles and standards, focusing on critical data quality dimensions
- Establish expectations for regulatory compliance, monitoring, and continuous improvement
Identifying Critical Data Elements
In the vast ocean of organizational data, not all elements are created equal. Identifying and prioritizing critical data elements is crucial for allocating resources effectively. This process involves:
- Collaborating with business units to understand data dependencies
- Assessing the impact of data elements on key business processes and decision making
- Prioritizing elements based on their potential to affect AI and analytics outcomes
Data Quality Dimensions
Identify the key dimensions of data quality that are most relevant to your organization’s goals and map it against the critical data elements. The most common dimensions are mentioned below. These quality dimensions guide the rule-setting process in ETL/ELT pipelines and ensure data fed to AI models is reliable.
| Data Quality Dimension | Description |
|---|---|
| Accuracy | Ensure that the data correctly reflects the real-world entities or events it is intended to represent |
| Completeness | Ensure that all required data fields are present and populated |
| Consistency | Ensure that data is consistent across all systems and does not contradict other data points |
| Timeliness | Ensure that the data is up-to-date and reflects the current state of affairs |
| Validity | Ensure that the data conforms to predefined formats, rules, and ranges |
| Uniqueness | Ensure that data does not contain unnecessary duplicates |
| Integrity | Ensure that relationships between data elements (e.g., foreign key constraints) are intact |
Data Contract: A Shared Responsibility
In the AI era, data quality is a shared responsibility between data producers and consumers. The data contract formalizes this relationship, serving as a binding agreement that ensures data integrity throughout its lifecycle. A well-structured data contract includes:
| Data Contract Items | Description |
|---|---|
| Metadata | Contract details, ownership, stakeholders, and timestamps |
| Dataset Schema | Detailed field definitions, types, and constraints |
| Data Quality Rules | Specific metrics for completeness, accuracy, and timeliness |
| Roles and Responsibilities | Clear delineation of data stewardship duties |
| Service Level Agreements | Expectations for availability, latency, and incident response |
Following is a simple example of data contract defining the schema and the data quality rules. Other formats can also be used as long the format enables automation.

Fig-2: Sample Data Contract
2. Automation Layer
Data quality issues can emerge at any stage of the data lifecycle. A comprehensive framework must address potential pitfalls at each phase to safeguard Data Quality Across the lifecycle. In the relentless pace of the AI-driven world, manual data quality processes to maintain Data Quality across the data lifecycle are not scalable. It is akin to bringing an abacus to a supercomputer showdown. By leveraging AI-powered data quality tools,
organizations can ensure that the key consideration under each stage is automated and scale with the changing needs of the organization.
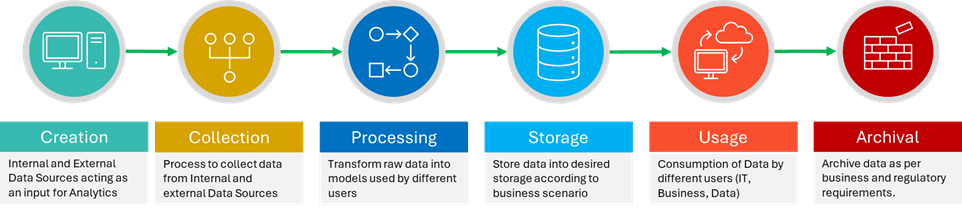
Fig-3: Data Life Cycle
Data Creation and Collection
At the source, data quality begins with rigorous standards and controls. Key considerations include:
- Implementing robust source validation protocols
- Enforcing schema consistency through automated checks
- Establishing guardrails for volume issues and infrastructure stability
Data Processing and Storage
As data flows through transformation pipelines, maintaining quality requires vigilance:
- Enforcing business rules and data integrity constraints
- Implementing anomaly detection to catch outliers and distribution shifts
- Ensuring schema evolution aligns with predefined data contracts
Data Usage and Analytics
In the hands of analysts and AI systems, data quality directly impacts decision-making:
- Validating aggregations and calculations against established benchmarks
- Implementing cross-system consistency checks
- Monitoring KPI thresholds and SLAs to ensure data reliability
Data Archival: Preserving Quality for the Long Term
Often overlooked, data archival is crucial for maintaining historical accuracy and
compliance:
- Synchronizing archived data structures with live datasets
- Incorporating archival audits into governance procedures
- Monitoring archival processes as part of overall data observability
AI Specific Quality Aspects
For Gen-AI apps themselves, data quality takes on new dimensions like nonrepresentation, bias, variance and data drift. Sone part of these dimensions can be checked in the data engineering data life cycle stages, but some are specific to AI/ML development. AI/ML has its own share of data collection and preparation. New data quality dimensions like non-representation, bias, variance and data drift have to be handled at this stage. Additionally, measures have to be taken during the model training and evaluation to check if the model is behaving as expected.
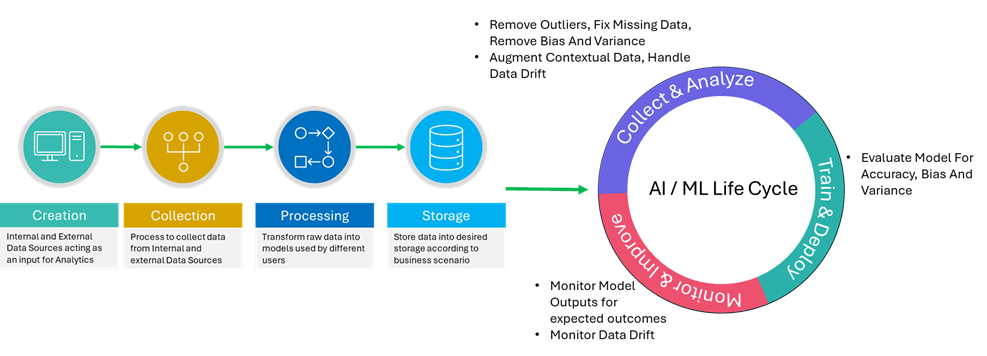
Fig-4: AI / ML Life Cycle
Bias Detection and Mitigation
AI systems can inadvertently perpetuate or amplify biases present in training data. A robust data quality framework must include:
- Automated bias detection algorithms
- Diverse data sourcing strategies to ensure representative datasets
- Regular audits of AI outputs for fairness and equity
- Establish cross-functional review boards to assess the societal impact of AI
systems
Handling Edge Cases and Rare Events
AI models excel at identifying patterns in large datasets but may falter with rare occurrences. To address this:
- Implement targeted data collection for underrepresented scenarios
- Develop synthetic data generation techniques to augment rare event data
- Establish ongoing monitoring for model performance on edge cases
Ensuring Data Diversity and Model Generalization
Overfitting remains a persistent challenge in AI development. Data quality frameworks
should incorporate:
- Cross-validation techniques to assess model generalization
- Data augmentation strategies to increase dataset diversity
- Continuous evaluation of model performance across varied data subsets
3. Governance Layer
A data quality framework is not a set-it-and-forget-it solution. It requires ongoing governance and a commitment to continuous improvement:
- Establish a cross-functional data governance team with clear roles and
responsibilities - Implement comprehensive data observability and monitoring solutions
- Regularly review and update data quality metrics and thresholds
- Foster a culture of data quality awareness across the organization
Toolset for implementing Data Quality Framework
| Issue Category | Description | Tools |
|---|---|---|
| Data Definition Changes | Changes in the structure of the source data assets | Define Data Contract and implement Schema enforcement |
| Volume Accuracy | Missing Files, Missing records in the data assets | Use off the shelf DQ libraries or custom written libraries |
| Business Rules | Issues with value constraints, referential integrity constraints, uniqueness, format, data duplication and completeness | Use off the shelf DQ libraries or custom written libraries |
| Data Anomalies | Missing values, outliers or issues with data distribution in a dataset not covered by business rules | Data Lineage tools , Data Profiling tools |
| Infrastructure Issues | Erroneous folder locations, missing folders, corrupted files, network connectivity issues | Use Data Contract to define the SLAs and implement custom code and observability tools to take preventive measures |
| Data Calculation & Aggregation | Erroneous Calculation or Aggregation errors in reports and data sharing | Reporting tools should be used for validation and reporting of business metrics |
| Data in Reports | Error propagating from previous stages leading to missing data in reports | Implement data lineage with off-the-shelf Data Governance tools to detect root cause for missing values. Use preventive measures to handle errors gracefully. |
| Consistency Across System | Mismatch in data across related systems | Define consistency and related SLAs as a part of the Data Contract. Create reports to monitor it. |
| Audit and Compliance Issues | Missed Audit and Compliance schedules | Define Audit and Compliance schedules as a part of the Data Contract |
| KPI Thresholds | Lack of monitoring of Data Quality KPI Thresholds | Define KPIs monitoring and related SLAs as a part of the Data Contract |
| Bias, Variance, Non-Representative Data | Issues with Prompts, RAG Data and Training Data leading to underfitting or overfitting of an AI/ ML Models | Prompt Management, Human in the loop approvals and python libraries to check bias and variances in the datasets. |
| Data Drift | Change in Data Distribution over time period | Use Use python libraries to check data drift and retrain the models |
| Data Quality Awareness | DQ implementation maturity due to lack of awareness and commitment among stakeholders | Do a Data Quality Assessment to find the gaps and the maturity level |
The Road Ahead: Data Quality as a Competitive Advantage
In an era where data is hailed as the new oil, data quality emerges as the refinery that transforms raw information into strategic gold. Organizations that prioritize data quality will find themselves not just surviving but thriving in the AI-driven future. As we stand on the cusp of unprecedented technological advancement, remember: the success of your AI initiatives is inextricably linked to the quality of your data foundation. By implementing a robust data quality framework, organizations can unlock the full potential of AI, drive innovation, and make decisions with confidence. In the words of W. Edwards Deming, “In God we trust. All others must bring data.” In the age of AI, we might add: “And that data better be impeccable.
Assess your data platform and processes today and start with Data Quality management journey.
References
- Dama DMBOK (Data Management Body of Knowledge)
- Gartner. “How to Create a Business Case for Data Quality Improvement.” 2022.
- IBM. “The Four V’s of Big Data.” 2023.
- NewVantage Partners. “Big Data and AI Executive Survey.” 2021.
- Ponemon Institute. “Data Risk in the Third-Party Ecosystem.” 2023.
- McKinsey & Company. “The AI Revolution in Analytics.” 2022.
- Harvard Business Review. “What’s Your Data Strategy?” 2021.
- World Economic Forum. “The Global Risks Report 2023.” 2023.
- MIT Sloan Management Review. “Building a Culture of Data Quality.” 2022
- Data Contracts 101: Importance, Validations & Best Practices
- Gretel.ai. Synthetic Data and the Data-centric Machine Learning Life Cycle
